
Robotic grasping is a cornerstone task for automation and manipulation, critical in domains spanning from industrial picking to service and humanoid robotics. Despite decades of research, achieving robust, general-purpose 6-degree-of-freedom (6-DOF) grasping remains a challenging open problem. Recently, NVIDIA unveiled GraspGen, a novel diffusion-based grasp generation framework that promises to bring state-of-the-art (SOTA) performance with unprecedented flexibility, scalability, and real-world reliability.
The Grasping Challenge and Motivation
Accurate and reliable grasp generation in 3D space—where grasp poses must be expressed in terms of position and orientation—requires algorithms that can generalize across unknown objects, diverse gripper types, and challenging environmental conditions including partial observations and clutter. Classical model-based grasp planners depend heavily on precise object pose estimation or multi-view scans, making them impractical for in-the-wild settings. Data-driven learning approaches show promise, but current methods tend to struggle with generalization and scalability, especially when shifting to new grippers or real-world cluttered environments.
Another limitation of many existing grasping systems is their dependency on large amounts of costly real-world data collection or domain-specific tuning. Collecting and annotating real grasp datasets is expensive and does not easily transfer between gripper types or scene complexities.
Key Idea: Large-Scale Simulation and Diffusion Model Generative Grasping
NVIDIA’s GraspGen pivots away from expensive real-world data collection towards leveraging large-scale synthetic data generation in simulation—particularly utilizing the vast diversity of object meshes from the Objaverse dataset (over 8,000 objects) and simulated gripper interactions (over 53 million grasps generated).
GraspGen formulates grasp generation as a denoising diffusion probabilistic model (DDPM) operating on the SE(3) pose space (comprising 3D rotations and translations). Diffusion models, well-established in image generation, iteratively refine random noise samples towards realistic grasp poses conditioned on an object-centric point cloud representation. This generative modeling approach naturally captures the multi-modal distribution of valid grasps on complex objects, enabling spatial diversity critical for handling clutter and task constraints.
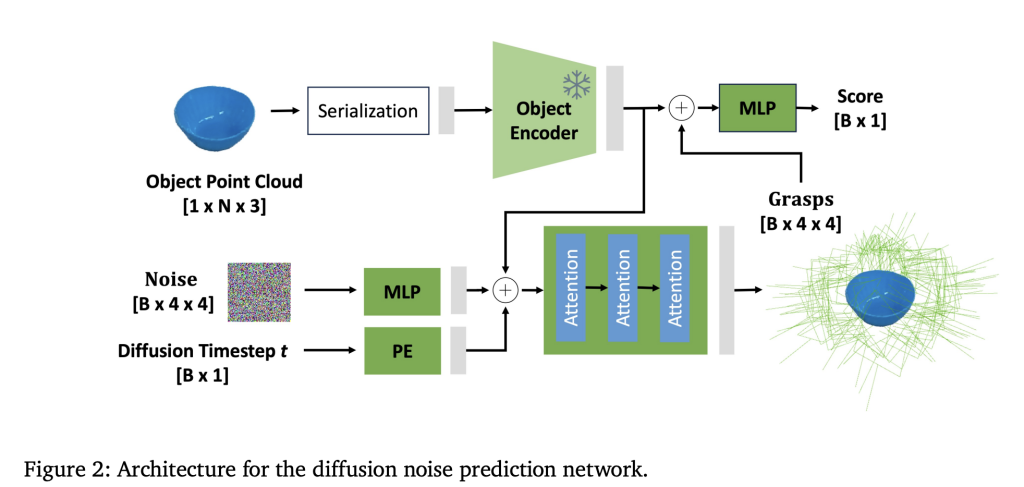
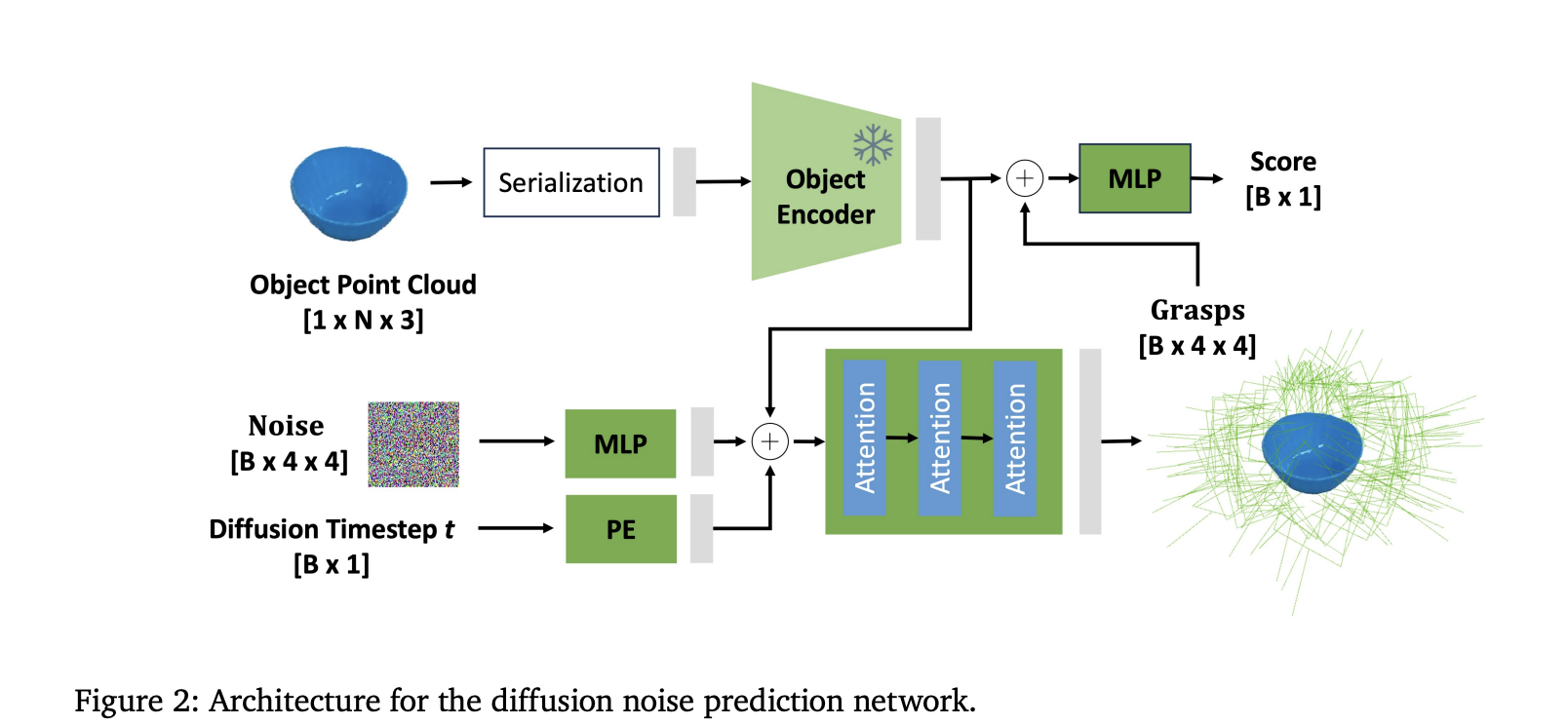
Architecting GraspGen: Diffusion Transformer and On-Generator Training
- Diffusion Transformer Encoder: GraspGen employs a novel architecture combining a powerful PointTransformerV3 (PTv3) backbone to encode raw, unstructured 3D point cloud inputs into latent representations, followed by iterative diffusion steps that predict noise residuals in the grasp pose space. This differs from prior works that rely on PointNet++ or contact-based grasp representations, delivering improved grasp quality and computational efficiency.
- On-Generator Training of Discriminator: GraspGen innovates on the grasp scorer or discriminator training paradigm. Instead of training on static offline datasets of successful/failed grasps, the discriminator learns on “on-generator” samples—grasp poses produced by the diffusion generative model during training. These on-generator grasps expose the discriminator to typical errors or model biases, such as grasps slightly in collision or outliers far from object surfaces, enabling it to better identify and filter false positives during inference.
- Efficient Weight Sharing: The discriminator reuses the frozen object encoder from the diffusion generator, requiring only a lightweight multilayer perceptron (MLP) trained from scratch for grasp success classification. This leads to a 21x reduction in memory consumption compared to prior discriminator architectures.
- Translation Normalization & Rotation Representations: To optimize network performance, the translation components of grasps are normalized based on dataset statistics, and rotations encoded via Lie algebra or 6D representations, ensuring stable and accurate pose prediction.
Multi-Embodiment Grasping and Environmental Flexibility
GraspGen is demonstrated across three gripper types:
- Parallel-jaw grippers (Franka Panda, Robotiq-2F-140)
- Suction grippers (modeled analytically)
- Multi-fingered grippers (planned future extensions)
Crucially, the framework generalizes to:
- Partial vs. Complete Point Clouds: It performs robustly on both single viewpoint observations with occlusions as well as fused multi-view point clouds.
- Single Objects and Cluttered Scenes: Evaluation on FetchBench, a challenging cluttered grasping benchmark, showed GraspGen achieving top task and grasp success rates.
- Sim-to-Real Transfer: Trained purely in simulation, GraspGen exhibited strong zero-shot transfer to real robotic platforms under noisy visual inputs, aided by augmentations simulating segmentation and sensor noise.
Benchmarking and Performance
- FetchBench Benchmark: In simulation evaluations covering 100 diverse cluttered scenes and over 6,000 grasp attempts, GraspGen outperformed state-of-the-art baselines like Contact-GraspNet and M2T2 by wide margins (task success improvement of nearly 17% over Contact-GraspNet). Even an oracle planner with ground-truth grasp poses struggled to push task success beyond 49%, highlighting the challenge.
- Precision-Coverage Gains: On standard benchmarks (ACRONYM dataset), GraspGen substantially improved grasp success precision and spatial coverage compared to prior diffusion and contact-point models, demonstrating higher diversity and quality of grasp proposals.
- Real Robot Experiments: Using a UR10 robot with RealSense depth sensing, GraspGen achieved 81.3% overall grasp success in various real-world settings (including clutter, baskets, shelves), exceeding M2T2 by 28%. It generated focused grasp poses exclusively on target objects, avoiding spurious grasps seen in scene-centric models.

Dataset Release and Open Source
NVIDIA released the GraspGen dataset publicly to foster community progress. It consists of approximately 53 million simulated grasps across 8,515 object meshes licensed under permissive Creative Commons policies. The dataset was generated using NVIDIA Isaac Sim with detailed physics-based grasp success labeling, including shaking tests for stability.
Alongside the dataset, the GraspGen codebase and pretrained models are available under open-source licenses at https://github.com/NVlabs/GraspGen, with additional project material at https://graspgen.github.io/.
Conclusion
GraspGen represents a major advance in 6-DOF robotic grasping, introducing a diffusion-based generative framework that outperforms prior methods while scaling across multiple grippers, scene complexities, and observability conditions. Its novel on-generator training recipe for grasp scoring decisively improves filtering of model errors, leading to dramatic gains in grasp success and task-level performance both in simulation and on real robots.
By publicly releasing both code and a massive synthetic grasp dataset, NVIDIA empowers the robotics community to further develop and apply these innovations. The GraspGen framework consolidates simulation, learning, and modular robotics components into a turnkey solution, advancing the vision of reliable, real-world robotic grasping as a broadly applicable foundational building block in general-purpose robotic manipulation.
Check out the Paper, Project and GitHub Page. All credit for this research goes to the researchers of this project. SUBSCRIBE NOW to our AI Newsletter

Michal Sutter is a data science professional with a Master of Science in Data Science from the University of Padova. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels at transforming complex datasets into actionable insights.






